
why AI adoption looks inconsistent even when everyone has the same tools
Structured prompts are the easy half. What you leave out is what actually breaks the answer.

Most people clean up how they ask an AI something — clear question, simple formatting — and still get a vague answer back. The reason isn’t the format. It’s what’s missing inside it: the actual facts of the situation, which the model has no way to know unless you say them.
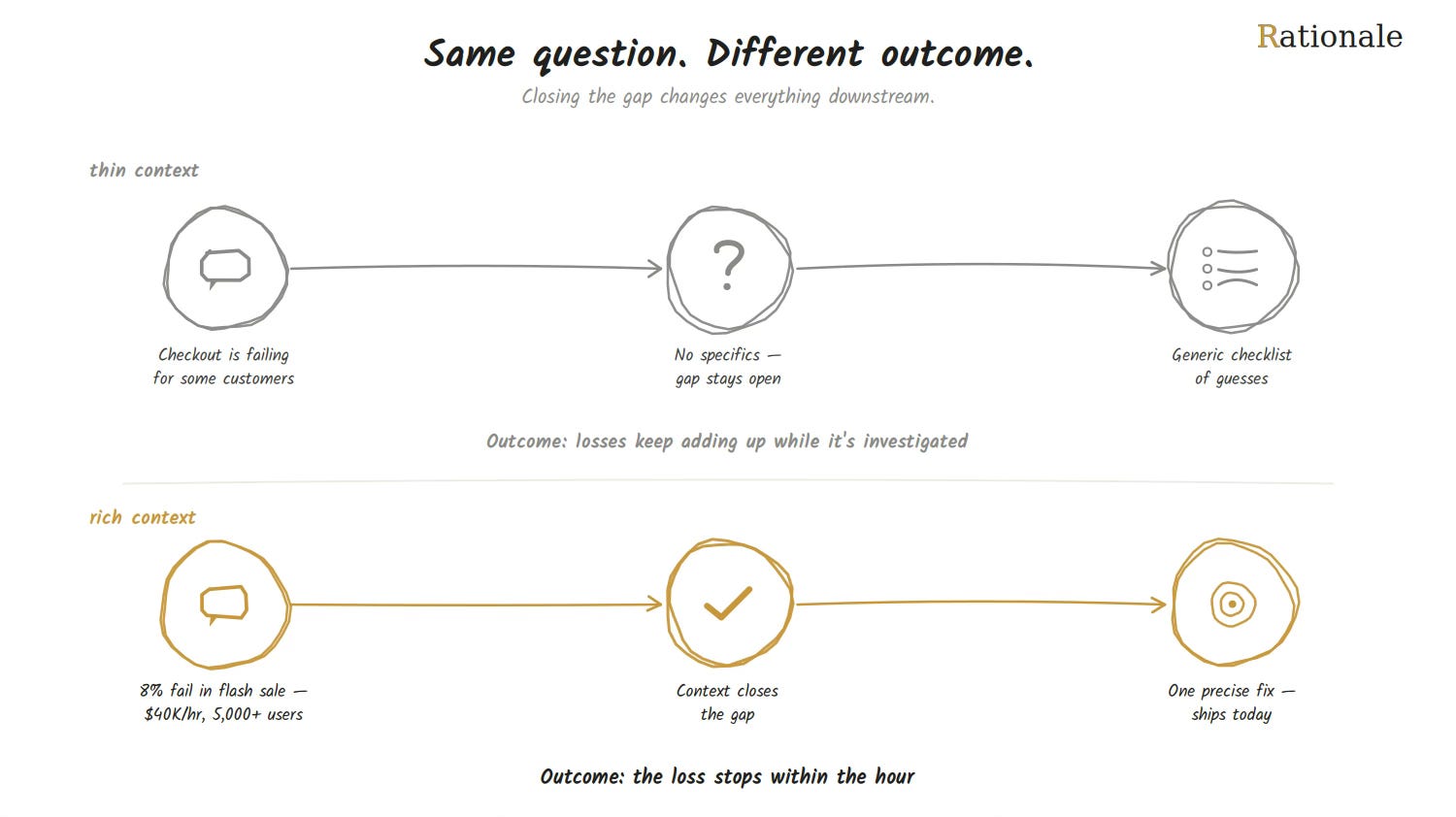
Here’s what that gap looks like in practice.
An engineer asks:
Problem: Checkout is failing for some customers.
What I need: Ways to fix it.
Clean format, clear ask. But the model still has to guess everything that actually matters — how often this happens, when it started, what’s already been ruled out. So it returns a checklist: check the payment gateway, check for timeouts, check error logs. None of it wrong. None of it pointed at this problem.
Now add context:
Problem: Checkout failures hit 8% during yesterday's flash sale — roughly $40,000/hour in lost orders.
Pattern: Failures cluster at the payment step once concurrent users pass 5,000.
Already checked: Payment gateway status (green), retried failed requests (still fail).
What I need: Most likely cause, given failures only appear under high concurrency.
Same format. Same problem, even. But now the model has enough to actually reason instead of guess, and lands on one specific diagnosis: the payment service is almost certainly running out of available connections under load, not failing because of the gateway itself — which means the fix is raising the connection pool limit or queuing requests past the threshold, not retrying or restarting anything. That’s not a smarter model. It’s the same model, given enough to reason with instead of guess from.
This is the part worth sitting with: rich context doesn’t just produce one better answer — it produces the same good answer every time you ask. A vague prompt gets a different generic response on every attempt, because nothing anchors it; the model invents its own framing from scratch each time. Specific context works like a fixed reference point. Feed in the same numbers and constraints, and the model reasons from your actual situation instead of re-guessing it. That consistency is the real value — not detail for its own sake, but an answer you can trust will hold up the next time you ask something similar.
Some of what belongs in that context isn’t written down anywhere — it’s the instinct that made you suspect concurrency before anything else, built from having watched systems buckle under load before. Naming that instinct in the prompt is what lets the model reason the way you would, instead of the way a generic checklist would.
For an individual, the habit is small: before asking, spend ten seconds listing what’s actually specific about this situation — the numbers, what’s already been ruled out. For someone running a team or a company, this is the gap behind why AI adoption looks inconsistent even when everyone has the same tools: it’s not a tooling problem, it’s a context problem, and it stays invisible until you go looking for it.
Format gets the model’s attention. Context is what it actually has to reason with.
— Arvind, Rationale One short issue a week. No jargon, no hype — just the reasoning behind what’s changing.