
Why the Loudest Detail Wins.
More detail helps an AI reason — until it doesn’t. Here’s where the line sits.

There’s a lesson that’s easy to over-apply: if context makes AI answers better, more context should make them better still. It doesn’t. Past a certain point, extra detail stops helping and starts burying the question — and the answer gets worse, not sharper. To see why, it helps to know what the model is actually doing with everything you hand it.
An AI model reads your entire message before it answers — every line, with equal seriousness, because it has no way to know in advance which parts matter. It isn’t skimming for the important bit; it’s working from all of it at once. That’s fine when everything you’ve included is relevant. It becomes a problem the moment it isn’t.
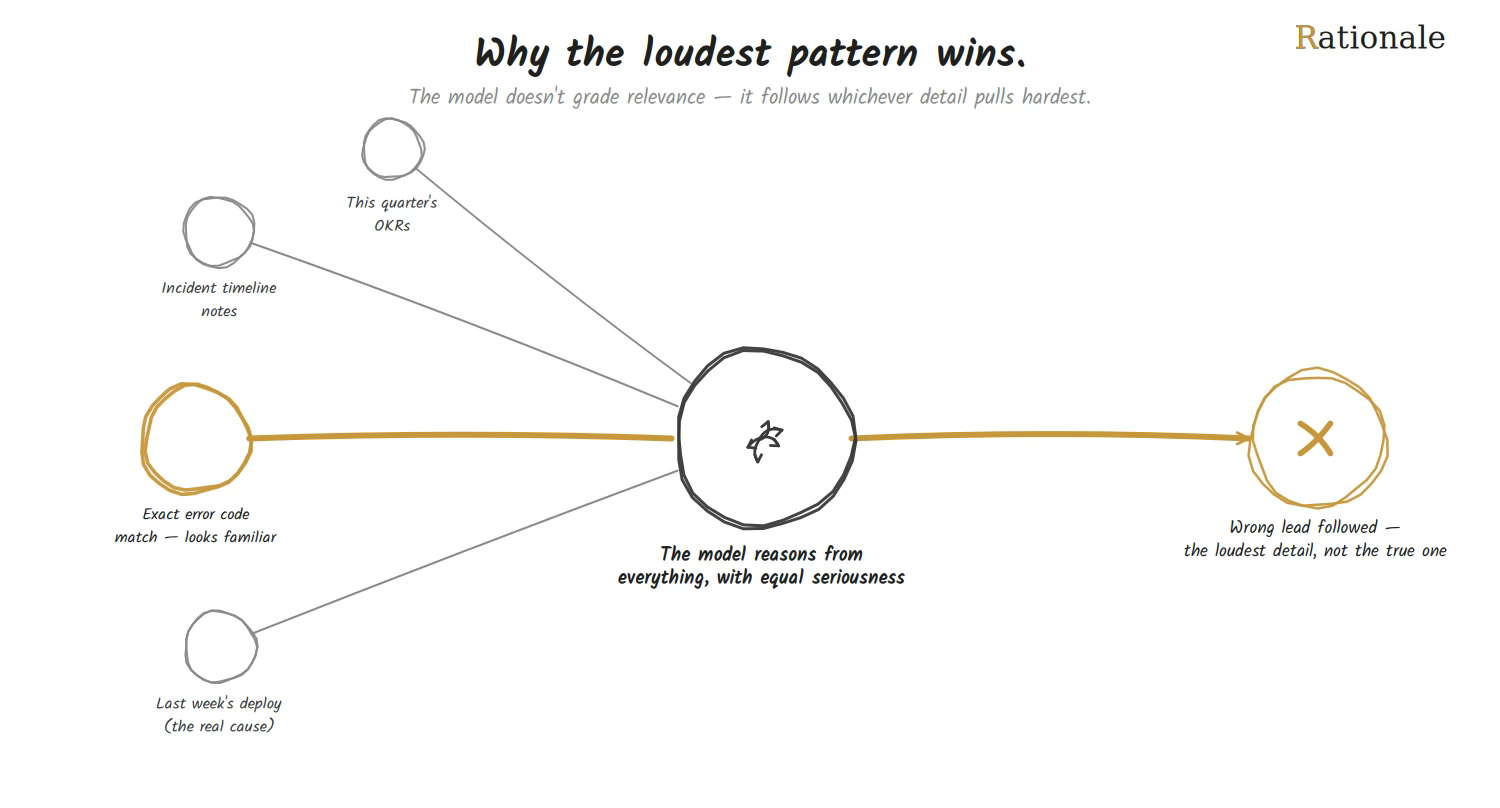
Here’s what that looks like in practice. An engineer trying to be thorough writes:
Incident notes: Reports started around 2pm. Checkout errors. On-call paged, checked dashboards, saw elevated error rates.
Related: March's outage had the same error code — caused by a stale DNS cache.
Also: Last week's deploy added a new fraud-check step to checkout.
Background: This quarter's goal is a 20% cut in checkout latency.
Problem: Checkout is failing for some customers.
Five facts, one of them real. Here’s what’s actually happening underneath: the model isn’t investigating this like a detective weighing clues one by one. It’s predicting the most natural-sounding continuation of everything in front of it — the same way it finishes a sentence, just at the scale of a whole answer. An exact, specific match, like the identical error code from March’s outage, is exactly the kind of strong, recognizable pattern that pulls a prediction toward it. So the model follows that thread: check DNS resolution, check the cache. The deploy note that’s actually relevant has no such pull — nothing marks it as different from the OKR line sitting right next to it, so it doesn’t stand out in the pattern being completed. The model isn’t being careless. It’s doing what it always does, finishing the most probable pattern in the text — and the prompt handed it a very convincing wrong one to finish.
Now the same problem, with only what’s load-bearing:
Problem: Checkout failures hit 8% during yesterday's flash sale — roughly $40,000/hour in lost orders.
Pattern: Failures cluster at the payment step once concurrent users pass 5,000.
Already checked: Payment gateway status (green), retried failed requests (still fail).
Three facts, and only one pattern available to complete: load rising alongside failures. There’s nothing else in the text pulling the prediction toward a different thread, so it follows the one that’s actually there instead of competing against a half-dozen others for which detail looks most like an answer.
The test for what belongs in a prompt isn’t length, it’s whether removing a line would change the answer. The March outage wouldn’t have changed it — it would have actively misled it. The deploy note might have, if it had been flagged instead of buried. Most people don’t run this test; they just add more, because more felt like the lesson last time.
For an individual, this is a single habit: before sending, ask what you’d lose by deleting each line. If nothing, cut it.
For someone leading a team, this failure is easy to miss, because it doesn’t look like a context problem — it looks like “the AI got something wrong,” and people quietly stop trusting it instead of fixing what they fed it. The fix isn’t less context. It’s teaching people to spot the one fact that’s actually doing work, and leave the rest out.
Format earns the model’s attention. Context gives it the facts. Knowing which facts to leave out is what makes the other two worth anything.
— Arvind, Rationale One short issue a week. No jargon, no hype — just the reasoning behind what’s changing.